1、Apache Spark是一个为速度和通用目标设计的集群计算平台。

从速度的角度看,Spark从流行的MapReduce模型继承而来,可以更有效地支持多种类型的计算,如交互式查询和流处理。速度在大数据集的处理中非常重要,它可以决定用户可以交互式地处理数据,还是等几分钟甚至几小时。Spark为速度提供的一个重要特性是其可以在内存中运行计算,即使对基于磁盘的复杂应用,Spark依然比MapReduce更有效。
从通用性来说,Spark可以处理之前需要多个独立的分布式系统来处理的任务,这些任务包括批处理应用、交互式算法、交互式查询和数据流。通过用同一个引擎支持这些任务,Spark使得合并不同的处理类型变得简单,而合并操作在生产数据分析中频繁使用。而且,Spark降低了维护不同工具的管理负担。
Spark被设计的高度易访问,用Python、Java、Scala和SQL提供简单的API,而且提供丰富的内建库。Spark也与其他大数据工具进行了集成。特别地,Spark可以运行在Hadoop的集群上,可以访问任何Hadoop的数据源,包括Cassandra。
2、基本原理
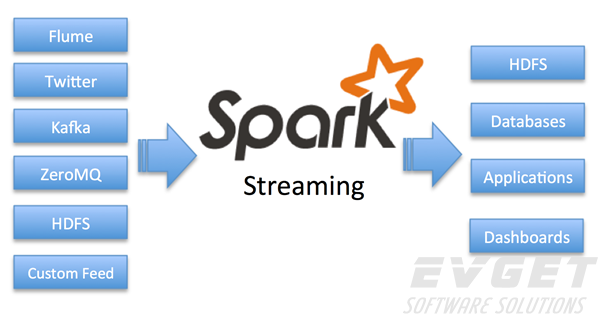
Spark Streaming: 构建在Spark上处理Stream数据的框架,基本的原理是将Stream数据分成小的时间片断(几秒),以类似batch批量处理的方式来处理这小部分数据。Spark Streaming构建在Spark上,一方面是因为Spark的低延迟执行引擎(100ms+),虽然比不上专门的流式数据处理软件,也可以用于实时计算,另一方面相比基于Record的其它处理框架(如Storm),一部分窄依赖的RDD数据集可以从源数据重新计算达到容错处理目的。此外小批量处理的方式使得它可以同时兼容批量和实时数据处理的逻辑和算法。方便了一些需要历史数据和实时数据联合分析的特定应用场合。其架构如下图所示:
3、Spark特点概括为“轻、灵、巧和快”。
轻:Spark 0.6核心代码有2万行,Hadoop 1.0为9万行,2.0为22万行。一方面,感谢Scala语言的简洁和丰富表达力;另一方面,Spark很好地利用了Hadoop和Mesos(伯克利 另一个进入孵化器的项目,主攻集群的动态资源管理)的基础设施。虽然很轻,但在容错设计上不打折扣。
灵:Spark 提供了不同层面的灵活性。在实现层,它完美演绎了Scala trait动态混入(mixin)策略(如可更换的集群调度器、序列化库);在原语(Primitive)层,它允许扩展新的数据算子 (operator)、新的数据源(如HDFS之外支持DynamoDB)、新的language bindings(Java和Python);在范式(Paradigm)层,Spark支持内存计算、多迭代批量处理、即席查询、流处理和图计算等多种 范式。
巧: 巧在借势和借力。Spark借Hadoop之势,与Hadoop无缝结合;接着Shark(Spark上的数据仓库实现)借了Hive的势;图计算借 用Pregel和PowerGraph的API以及PowerGraph的点分割思想。一切的一切,都借助了Scala(被广泛誉为Java的未来取代 者)之势:Spark编程的Look'n'Feel就是原汁原味的Scala,无论是语法还是API。在实现上,又能灵巧借力。为支持交互式编 程,Spark只需对Scala的Shell小做修改(相比之下,微软为支持JavaScript Console对MapReduce交互式编程,不仅要跨越Java和JavaScript的思维屏障,在实现上还要大动干戈)。
快:Spark 对小数据集能达到亚秒级的延迟,这对于Hadoop MapReduce是无法想象的(由于“心跳”间隔机制,仅任务启动就有数秒的延迟)。就大数据集而言,对典型的迭代机器 学习、即席查询(ad-hoc query)、图计算等应用,Spark版本比基于MapReduce、Hive和Pregel的实现快上十倍到百倍。其中内存计算、数据本地性 (locality)和传输优化、调度优化等该居首功,也与设计伊始即秉持的轻量理念不无关系。
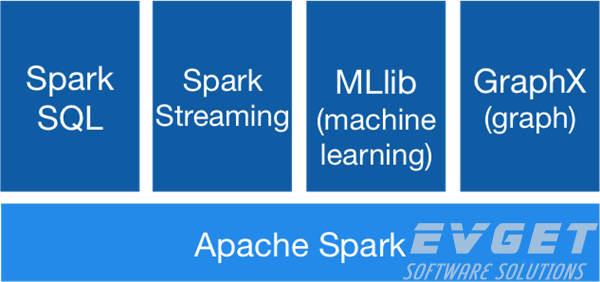
4、Spark的核心组件
Spark核心组件包含Spark的基本功能,有任务调度组件、内存管理组件、容错恢复组件、与存储系统交互的组件等。Spark核心组件提供了定义弹性分布式数据集(resilient distributed datasets,RDDs)的API,这组API是Spark主要的编程抽象。RDDs表示分布在多个不同机器节点上,可以被并行处理的数据集合。Spark核心组件提供许多API来创建和操作这些集合。
Spark SQL
Spark SQL是Spark用来处理结构化数据的包。它使得可以像Hive查询语言(Hive Query Language, HQL)一样通过SQL语句来查询数据,支持多种数据源,包括Hive表、Parquet和JSON。除了为Spark提供一个SQL接口外,Spark SQL允许开发人员将SQL查询和由RDDs通过Python、Java和Scala支持的数据编程操作混合进一个单一的应用中,进而将SQL与复杂的分析结合。与计算密集型环境紧密集成使得Spark SQL不同于任何其他开源的数据仓库工具。Spark SQL在Spark 1.0版本中引入Spark。
Shark是一个较老的由加利福尼亚大学和伯克利大学开发的Spark上的SQL项目,通过修改Hive而运行在Spark上。现在已经被Spark SQL取代,以提供与Spark引擎和API更好的集成。
Spark流(Spark Streaming)
Spark流作为Spark的一个组件,可以处理实时流数据。流数据的例子有生产环境的Web服务器生成的日志文件,用户向一个Web服务请求包含状态更新的消息。Spark流提供一个和Spark核心RDD API非常匹配的操作数据流的API,使得编程人员可以更容易地了解项目,并且可以在操作内存数据、磁盘数据、实时数据的应用之间快速切换。Spark流被设计为和Spark核心组件提供相同级别的容错性,吞吐量和可伸缩性。
MLlib
Spark包含一个叫做MLlib的关于机器学习的库。MLlib提供多种类型的机器学习算法,包括分类、回归、聚类和协同过滤,并支持模型评估和数据导入功能。MLlib也提供一个低层的机器学习原语,包括一个通用的梯度下降优化算法。所有这些方法都可以应用到一个集群上。
GraphX
GraphX是一个操作图(如社交网络的好友图)和执行基于图的并行计算的库。与Spark流和Spark SQL类似,GraphX扩展了Spark RDD API,允许我们用和每个节点和边绑定的任意属性来创建一个有向图。GraphX也提供了各种各样的操作图的操作符,以及关于通用图算法的一个库。
集群管理器Cluster Managers
在底层,Spark可以有效地从一个计算节点扩展到成百上千个节点。为了在最大化灵活性的同时达到这个目标,Spark可以运行在多个集群管理器上,包括Hadoop YARN,Apache Mesos和一个包含在Spark中的叫做独立调度器的简易的集群管理器。如果你在一个空的机器群上安装Spark,独立调度器提供一个简单的方式;如果你已经有一个Hadoop YARN或Mesos集群,Spark支持你的应用允许在这些集群管理器上。第七章给出了不同的选择,以及如何选择正确的集群管理器。
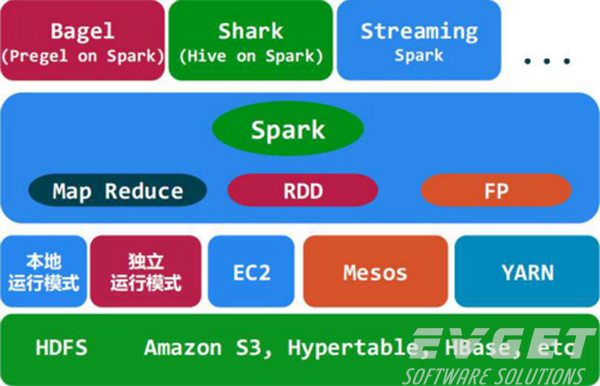
5、Spark的生态系统
Shark ( Hive on Spark): Shark基本上就是在Spark的框架基础上提供和Hive一样的H iveQL命令接口,为了最大程度的保持和Hive的兼容性,Shark使用了Hive的API来实现query Parsing和 Logic Plan generation,最后的PhysicalPlan execution阶段用Spark代替Hadoop MapReduce。通过配置Shark参数,Shark可以自动在内存中缓存特定的RDD,实现数据重用,进而加快特定数据集的检索。同时,Shark通过UDF用户自定义函数实现特定的数据分析学习算法,使得SQL数据查询和运算分析能结合在一起,最大化RDD的重复使用。
Spark streaming: 构建在Spark上处理Stream数据的框架,基本的原理是将Stream数据分成小的时间片断(几秒),以类似batch批量处理的方式来处理这小部分数据。Spark Streaming构建在Spark上,一方面是因为Spark的低延迟执行引擎(100ms+)可以用于实时计算,另一方面相比基于Record的其它处理框架(如Storm),RDD数据集更容易做高效的容错处理。此外小批量处理的方式使得它可以同时兼容批量和实时数据处理的逻辑和算法。方便了一些需要历史数据和实时数据联合分析的特定应用场合。
Bagel: Pregel on Spark,可以用Spark进行图计算,这是个非常有用的小项目。Bagel自带了一个例子,实现了Google的PageRank算法。

6、Spark历史简介
Spark是一个开源项目,由多个不同的开发者社区进行维护。如果你或你的团队第一次使用Spark,你可能对它的历史感兴趣。Spark由UC伯克利RAD实验室(现在是AMP实验室)在2009年作为一个研究项目创建。实验室的研究人员之前基于Hadoop MapReduce工作,他们发现MapReduce对于迭代和交互式计算任务效率不高。因此,在开始阶段,Spark主要为交互式查询和迭代算法设计,支持内存存储和高效的容错恢复。
在2009年Spark创建不久后,就有关于Spark的学术性文章发表,在一些特定任务中,Spark的速度可以达到MapReduce的10-20倍。
一部分Spark的用户是UC伯克利的其他组,包括机器学习的研究人员,如Mobile Millennium项目组,该组用Spark来监控和预测旧金山湾区的交通拥堵情况。在一个非常短的时间内,许多外部的机构开始使用Spark,现在,已经有超过50个机构在使用Spark,还有一些机构公布了他们在Spark Meetups和Spark Summit等Spark社区的使用情况。Spark主要的贡献者有Databricks,雅虎和因特尔。
在2011年,AMP实验室开始开发Spark上的上层组件,如Shark和Spark流。所有这些组件有时被称为伯克利数据分析栈(Berkeley Data Analytics Stack,BDAS)。
Spark在2010年3月开源,在2014年6月移入Apache软件基金会,现在是其顶级项目。
参考资料:
1、百度百科
2、Open经验库
3、36大数据


推荐机械工业出版社的spark经典书籍,《spark大数据处理》,可在线阅读。
文不对题