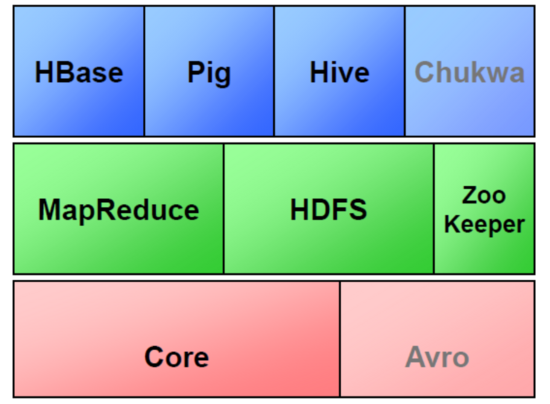
1.Hadoop是什么?
适合大数据的分布式存储与计算平台
HDFS: Hadoop Distributed File System分布式文件系统
MapReduce:并行计算框架
2.Hadoop生态圈
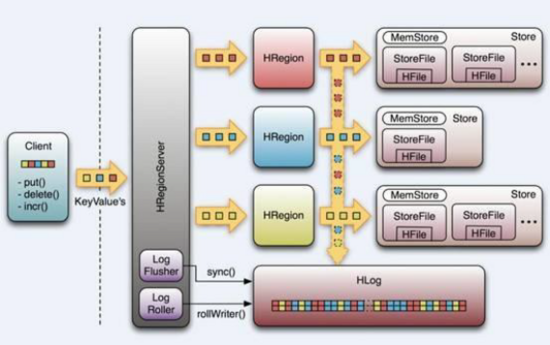
①HBase
Google Bigtable的开源实现
列式数据库
可集群化
可以使用shell、web、api等多种方式访问
适合高读写(insert)的场景
HQL查询语言
NoSQL的典型代表产品
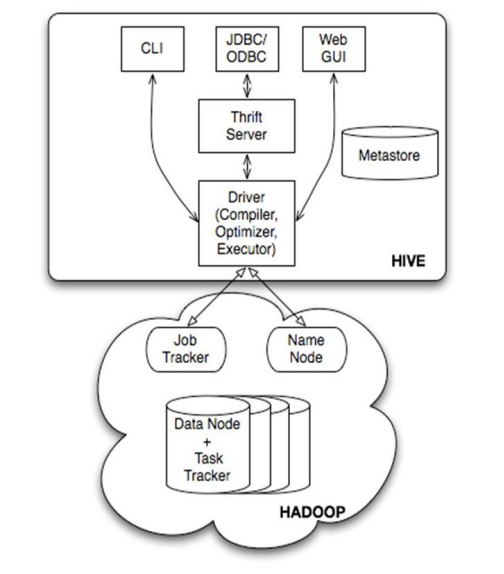
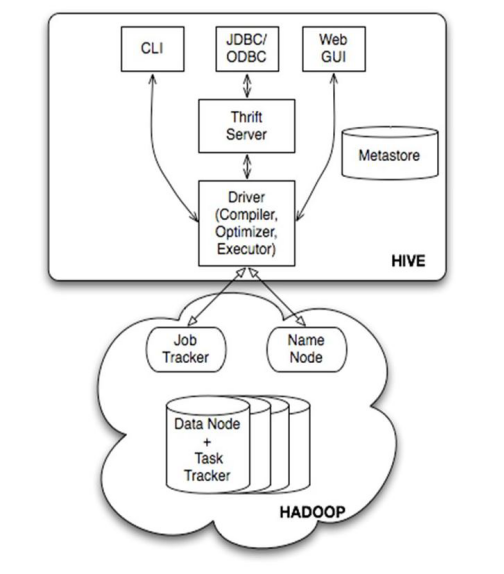
②Hive
数据仓库工具。可以把Hadoop下的原始结构化数据变成Hive中的表
支持一种与SQL几乎完全相同的语言HiveQL。除了不支持更新、索引和事务,几乎SQL的其它特征都能支持
可以看成是从SQL到Map-Reduce的映射器
提供shell、JDBC/ODBC、Thrift、Web等接口
③Zookeeper
Google Chubby的开源实现
用于协调分布式系统上的各种服务。例如确认消息是否准确到达,防止单点失效,处理负载均衡等
应用场景:Hbase,实现Namenode自动切换
工作原理:领导者,跟随者以及选举过程
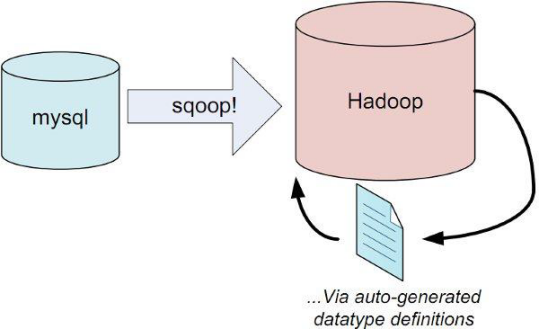
④Sqoop
用于在Hadoop和关系型数据库之间交换数据
通过JDBC接口连入关系型数据库
⑤Chukwa
架构在Hadoop之上的数据采集与分析框架
主要进行日志采集和分析
通过安装在收集节点的“代理”采集最原始的日志数据
代理将数据发给收集器
收集器定时将数据写入Hadoop集群
指定定时启动的Map-Reduce作业队数据进行加工处理和分析

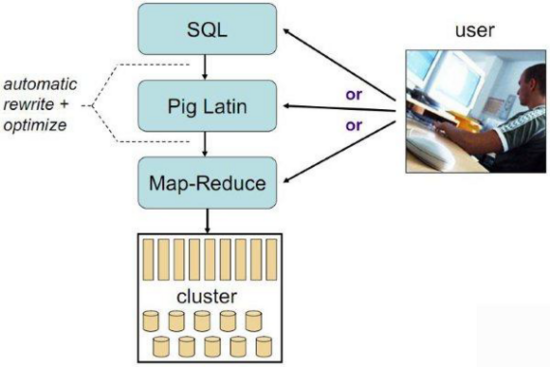
⑥Pig
Hadoop客户端
使用类似于SQL的面向数据流的语言Pig Latin
Pig Latin可以完成排序,过滤,求和,聚组,关联等操作,可以支持自定义函数
Pig自动把Pig Latin映射为Map-Reduce作业上传到集群运行,减少用户编写Java程序的苦恼
⑦Avro
数据序列化工具,由Hadoop的创始人Doug Cutting主持开发
用于支持大批量数据交换的应用。支持二进制序列化方式,可以便捷,快速地处理大量数据
动态语言友好,Avro提供的机制使动态语言可以方便地处理 Avro数据。
Thrift接口

⑧Cassandra
NoSQL,分布式的Key-Value型数据库,由Facebook贡献
与Hbase类似,也是借鉴Google Bigtable的思想体系
只有顺序写,没有随机写的设计,满足高负荷情形的性能需求

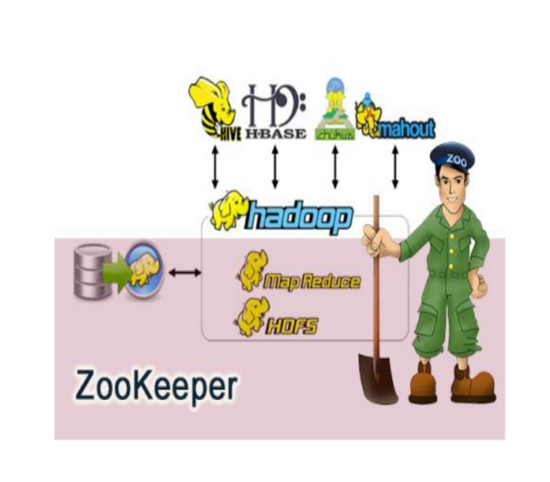
3.Hadoop生态圈流程图
慧都控件网超级促销月,全场6折起,豪礼抢不停>>>
截止时间:2016年11月30日
更多大数据与分析相关行业资讯、解决方案、案例、教程等请点击查看>>>
详情请咨询在线客服!
客服热线:023-66090381



