Node.JS与USB接口通信:检测U盘/移动硬盘插拔事件和发送接数据 在做嵌入式开发时,我们经常需要能够侦听USB端口的热插拔事件。目前node.js本身是不提供这类系统事件的接口的。不过已经有人用node.js和c/c++来侦听USB的系统事件,并将其打包进了NPM。
使用
var usb = require('usb')
usb.on('attach', function(device) {
});
usb.on('detach', function(device) {
}); NodeJS动态传参特性:不定个数参数的省略,默认值与解构 在Javascript中普遍模式是将一个对象作为配置可选项,以前,这些选项得手工从对象中分解出来然后分配给相应变量。
function doTask (who, options) {
options = options || ''
var name = options.name
var time = options.time
}
现在只需要一行即可:
function doTask (who, options = {}) {
var { name, time } = options
} 40行JavaScript代码实现的3D旋转魔方动画效果 这是2016年JS1k上传的作品,用几十行代码实现的一个3D旋转魔方:
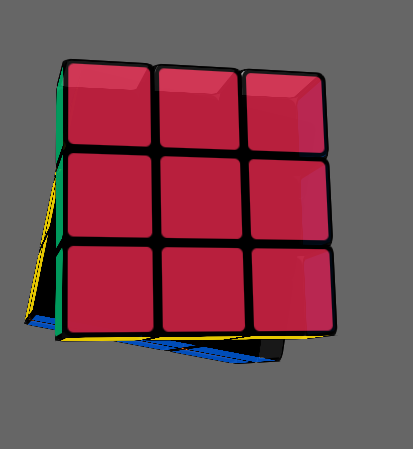
垄断"开源硬件"树莓派芯片的供应商博通要收购高通了 然而树莓派并非是真正开源的,因为其芯片一直是博通 (Broadcom) 控制的,是特供版,树莓派 3 采用了最新的 BCM2837 芯片,但这个芯片的 BootLoader 引导程序和手册等重要内容都是保密的。可以说树莓派的出货一直是被博通牢牢掌控的。Boradcom目前市值1000多忆美元左右。其中一半以上的利润来自中国。
GitHub2017年度开发者报告 JavaScript依然遥遥领先Python突飞猛进 GitHub Universe 是 GitHub 的年度盛会,今年10月10-12日,GitHub Universe 大会在旧金山召开。同时,GitHub 也在其官网发布了 2017 年年度数据报告 —— GitHub Octoverse 报告。
可以看到,Python 已代替 Java 从去年的第三突进了第二,相比去年它新增了 40% 的 Pull Request。越来越多开发者在感慨“人生苦短” 了?
Java 则被挤下到第三位,不过 Java 9 刚发布不久,而且它的模块化特性深受开发者喜爱,霸主地位还是很难撼动的。
排名第一的依然是 JavaScript,而且远甩其他语言好几条街。联想到近几年前端技术的火热发展,所以并没有太大意外。
从 Node 到 Go:一个粗略的比较—GO平均性能比JavaScript快十几倍 虽然我在大学时期和刚刚工作的一些时间在使用更严谨的编译语言,比如 C++ 和 C#,而后来我开始使用 JavaScript。我很喜欢它的自由和灵活,但是我最近开始怀念静态和结构化的语言,因为当时有一个同事让我对 Go 语言产生了兴趣。
我从写 JavaScript 到写 Go,我发现两种语言有很多相似之处。两者学习起来都很快并且易于上手,都具有充满表现力的语法,并且在开发者社区中都有很多工作机会。没有完美的编程语言,所以你应该总是选择一个适合手头项目的语言。在这篇文章中,我将要说明这两种语言深层次上的关键区别,希望能鼓励没有用过 Go 语言的用户有机会使用 Go 。
阿里涉嫌抄袭创业公司产品:在今天这个故事里,阿里巴巴就是四十大盗 昨天吴亮在知乎上爆料,阿里涉嫌以合作的名义套取『你今天真好看』的设计和技术方案,并全盘抄袭。
不好意思打扰大家的时间线了,因为工作太忙,我已经很久没有在知乎活跃,没想到今天因为这么一件事重回到大家的视野中。
在过去三年里,我和我们小团队,一直在埋头做一款叫『你今天真好看』的APP。关于我们创作它的故事,我之前的专栏里也有介绍,这里就不赘述了。
写这篇文章,是因为我们遇上了一件很糟糕的事。太令人难以置信了,我自己连说出来都觉得心很累:
阿里巴巴竟然以合作的名义,拿走了我们的技术方案,全盘抄袭了我们的APP。
迫于社区压力:React(Native)16将更换成MIT开源协议 近日,Facebook宣布 React,Jest,Flow 和 Immutable.js开源项目将更换成MIT协议,MIT是非常宽松的许可协议,开发者使用这些开源项目将不再面临法律风险。使用新协议的 React 16 将于下周发布。
Node也许不是构建大型服务的最佳选择—Node之父Ryan Dahl访谈录 我认为 Node 的非阻塞范式非常适用于没有线程的 JavaScript。而且我认为,回调有很多问题,您必须跳入许多匿名函数才能完成工作。对使用 async 关键字,异步功能的现阶段 JavaScript 来说,这个问题已经缓解很多了。因此一些较新版本的 JavaScript 使得完成工作更容易。我认为 Node 不是构建庞大服务器网络的最佳系统,我一定会用 Go 去做,这基本上是我离开 Node 的原因。实际上, Node 不是最好的服务器端系统。
WordPress、百度宣布停止使用React(Native)开源项目,Facebook开源专利许可潜在的法律风险 7月16日Apache 基金会在 把 Facebook BSD+Patents 开源许可加入了禁止名单中。因为著名的开源项目 React 是基于这个协议的,那就意味着 Apache 基金会下所有开源项目都需要在 8 月 31 号前移除 React 相关代码。
BSD 的授权本身是简单,开放,没有限制的,但 Facebook BSD+Patents 在此基础增加了一个 专利协议。
简单来说就是使用React及其衍生项目的开发者,一旦对 Facebook 发起专利诉讼,则将失去使用 Ract 开源项目的的权利。Facebook将能够向你发起侵权诉讼。

