未发布 10个学习JavaScript的免费在线资源丨附地址 我们都听说过“ JavaScript ” 这个术语,但我们中只有少数人知道它的用法和应用。这里的“我们中的少数”是指技术青年、网络程序员和IT专业人员。但是,对于外行来说,“JavaScript”只不过是一个与计算机编程相关的复杂术语。
那么,什么是JavaScript?如果你希望在计算机领域工作,那么你不能错过JavaScript。它是最着名的网页脚本语言。它也广泛用于游戏开发以及桌面和移动应用程序的创建。此外,网站上很多基本功能如下拉菜单、视觉效果、验证数据等都是使用JavaScript创建的。当然,这只是一个概述。
学习JavaScript最好的方法之一是通过视频教程进行在线学习。这里列出十个免费在线学习JavaScript的地址,让你的学习更方便、更有效。
未发布 AutoVue现在支持本地2D Creo / ProE图纸 随着最新的AutoVue 21.0.1 RUP3的发布,Oracle重新引入了对2D Creo / ProE图纸的本地支持。
为了提供一些上下文,Creo / ProE工程图包含完整的“本地”数据以及图形的预处理“显示列表”版本。使用“显示列表”往往会呈现绘图的最高保真度,但是在某些情况下不会出现,或者不会保持最新。
因此,AutoVue将优先显示“显示列表”版本。但是,如果显示列表不存在,或者如果检测到它已过时,将显示原始数据,以确保用户看到最新的信息。
未发布 全面的.NET图像处理包DotImage v10.7.0.7发布丨附下载 DotImage
Atalasoft DotImage 是一款功能完善的图像处理包,它主要针对.NET的开发。它为基于.Net框架开发的Windows应用程序以及基于IE的Asp.Net程序提供高级的图像处理功能。DotImage 提供了很多Microsoft .NET Framework一样的设计模式,并向开发者提供功能丰富,高性能,授权方式灵活的对象模式。
DotImage v10.7.0.7更新内容
v10.7.0.7中的修复的问题
- [TiffDecoder]Customer图片会导致TiffDecoder出现SEHException异常。
- [AdvancedDocClean] LineRemovalCommand在某些图像上会引起不可修复的System.AccessViolationException,从而破坏主机进程。
- [AbbyyEngine] OcrTableRegion.Cells没有被填充。
- WebDocumentViewer getDocumentInfo对removePage的调用不成功。
上一个版本中修复的问题
- 在特定的PDF中使用修复功能会导致新版本出现异常。
- [MVC] NuGet库中缺少Atalasoft.dotImage.WebControls.MVC(包括x86和x64)。
- [WDV] Async方法可能会在浏览器页面刷新期间/之后引起控制台发生错误。
- 使用PdfDocument.Save格式保存时,Multipage PDF页面会引用前几页的资源。
- 保存PDF时,无效的PDF属性值会引起异常。
- [PdfAnnotationDataExporter]使用OverwriteExistingAnnotations = true保存到特定图层时,会覆盖掉上一层。
- PDF417条形码不可读取。
- Customer DWG文件在DwgDecoder中呈现时丢失图像。
- WebDocumentViewer会调用触发了ThreadAbortException的Response.End。
- PdfDocument.Repair对于某些格式不正确的链接可能会删除而不是修复。
- [PdfTextDocument]文本提取结果在某些文档上使用时会丢失内容。
- 当SelectionMode = ThumbnailSelectionMode.MultiSelect时WinForms ThumbnailView / FolderThumbnailView SelectionIndexChanged会触发两次。
- RawDecoder注册时,Customer file会引起System.AccessViolation异常。
- [PdfGeneratedDocument] PdfTextLine会忽略通过构造函数传递的FillColor和OutlineColor值。
- [PdfDocument]一些PDF文件在PdfDocument中打开时会发生StackOverflow问题。
- [PdfDocument]使用PdfDocument / PdfAnnotationDataImporter打开一些PDF时会出现Overflow问题。
- WebDocumentThumbnailer:当tabular:true set时,滚动条未正确更新。
- 客户在Logger中报告的竞争条件/非线程安全行为。
- “不支持Colourspace转换”的Customer tiffs无法打开。
- 755266:WDV - 打开non-relative web根路径将导致WDV保存失败。
- [PdfDocument]如果我们多次将新页面添加到文档时,Adobe Acrobat将无法读取pdf文件。
- 只有页面可见时,WebDocumentViewer Rotate方法才会更新。
- [OfficeDecoder]无论解码器分辨率如何设置,Office文件始终呈现默认的DPI(大多数系统上为96)。
- [PdfEncoder]使用PdfCompressionMode.Segmented保存大文件(大量页面)会发生内存的问题。
- [BarCodeReader] DataMatrix条形码读取速度非常慢
- PdfCompressionMode.Segmented强制将灰度图像变为黑白,且这种行为没有记录。
- PdfDocument打开/保存时Customer PDF被损坏。
- [OfficeDecoder]部分office文件的表格标题中缺少内容。
- 带有AnnotationStreamWritten事件的WDV 10.7中的行为发生变化。
- 载入注释中的WDV regression。
- [DotTwain] HP scanners DeviceEvent 会使device.State进入无效状态。
- Barcoding.Reading.BarcodeReader没有读取到相应的客户代码。
- 10.7 WDV更改会破坏WingScan-only的许可。
- [PdfAnnotationDataExporter] EmbeddedImageAnnotation会增加目标PDF文件大小。
- [BarCodeReader] - 在其他引擎中读取的PDF-417条形码的Customer images在BarCodeReader中无法读取。
- [BarCodeReader]当前的BarCodeReader引擎无法读取旧的9.x(Inlite)引擎读取的条形码的全部内容。
- [PdfDocument]Customer PDF会引起关于MLPdfLabColorSpace的PdfException异常。修复后提示成功,但所有内容也会丢失。
未发布 CAD .NET v12发布,提高GDI+可视化速度并可导入AutoCAD®DWG 2018丨附下载
CAD .NET新版本大大提高了GDI+可视化的速度。当加载具有复杂结构的大文件时可以很明确的体验到。例如,包含大量实体的一些文件的可视化速度现在提升了十倍。
更重要的是,CAD .NET现在可以导入最近发布的最新DWG版本的AutoCAD®DWG 2018。
此外,CAD .NET使用非Unicode SHX文本和形状的方式已经大大改善。这种改进对于使用本地非Unicode字体的系统尤其重要,例如德语、法语、希伯来语和其他语言的特殊字符。
CAD .NET 12包含的改进和修复的内容列表:
GDI+可视化速度大大提高
导入AutoCAD®DWG 2018
改进非Unicode SHX文本/形状支持
Bug修复
试用、下载、了解更多产品信息请点击"咨询在线客服"
未发布 JavaScript网络摄像头和视频捕获Dynamsoft Camera SDK v5.2发布 JavaScript网络摄像头和视频捕获Dynamsoft Camera SDK v5.2发布。新版本将Windows服务部分重组为common Dynamsoft Service,由其他Dynamsoft Web-based Imaging SDKs共享。使用common Dynamsoft Service,你可以轻松地在应用程序中实现多个Dynamsoft HTML5 / JavaScript imaging SDK。
【Dynamsoft Camera SDK v5.2点击下载>>>】
例如,你的Web应用程序可能需要实现以下功能:
- 扫描纸质文件
- 从网络摄像头中捕获图像
- 从扫描的文档或网络摄像头中读取条形码
你可以同时使用Dynamic Web TWAIN、Dynamsoft Camera SDK和Dynamsoft Barcode Reader来满足你的要求。他们共享common Dynamsoft Service进行通信。你也可以轻松地在产品之间共享图像数据。
v5.2更新内容
- 更改了摄像头授权对话框的行为,默认情况下不会显示。
- 添加了一个新的方法dynamsoft.dcsEnv.setLanguage,用来设置摄像头授权对话框中使用的语言。
- 添加了一个新的方法getImagePartUrl,根据图像查看器中的索引获取图像的URL。
未发布 Edraw Max(亿图图示)新技能:在软件上进行反激活 Edraw Max(亿图图示)8.7以上的版本,新增了“反激活”功能,也就意味这用户以后可以自主进行反激活。Edraw Max(亿图图示)一个产品秘钥支持两台电脑同时使用,如果超过两台电脑,则需要清除其中一台电脑的绑定,也就是反激活操作。又或者因为某些原因导致电脑需要重装系统,那么,你也需要进行反激活。否则,就会出现产品秘钥失效的情况。
本文将详细介绍Edraw Max(亿图图示)8.7以上版本在软件上应该如何进行反激活操作!目前Edraw Max(亿图图示)在线订购享75折优惠活动正在进行中,欢迎您下载、购买进行运用!
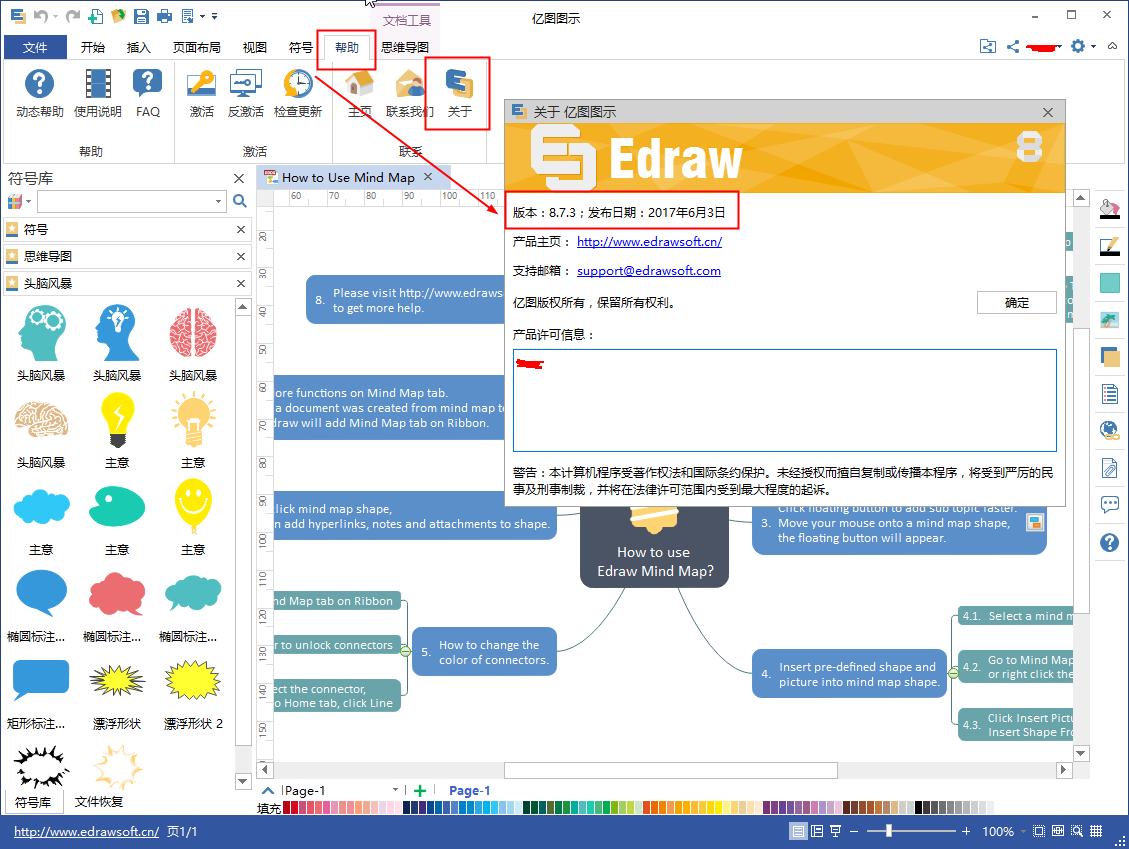
首先,请确定软件是8.7及其以上版本,软件版本查看如下图所示:
如果已经是8.7以上版本的,就可以通过软件一键“反激活”按钮,来进行反激活操作了。
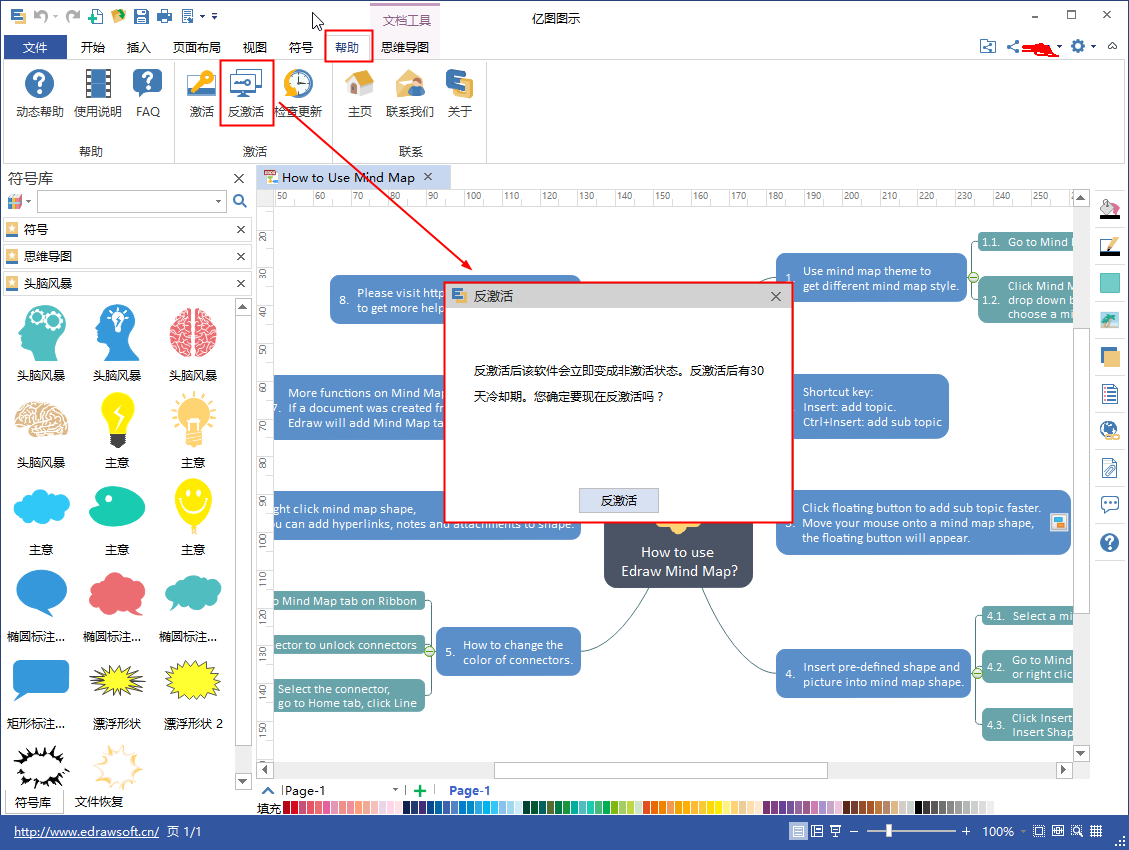
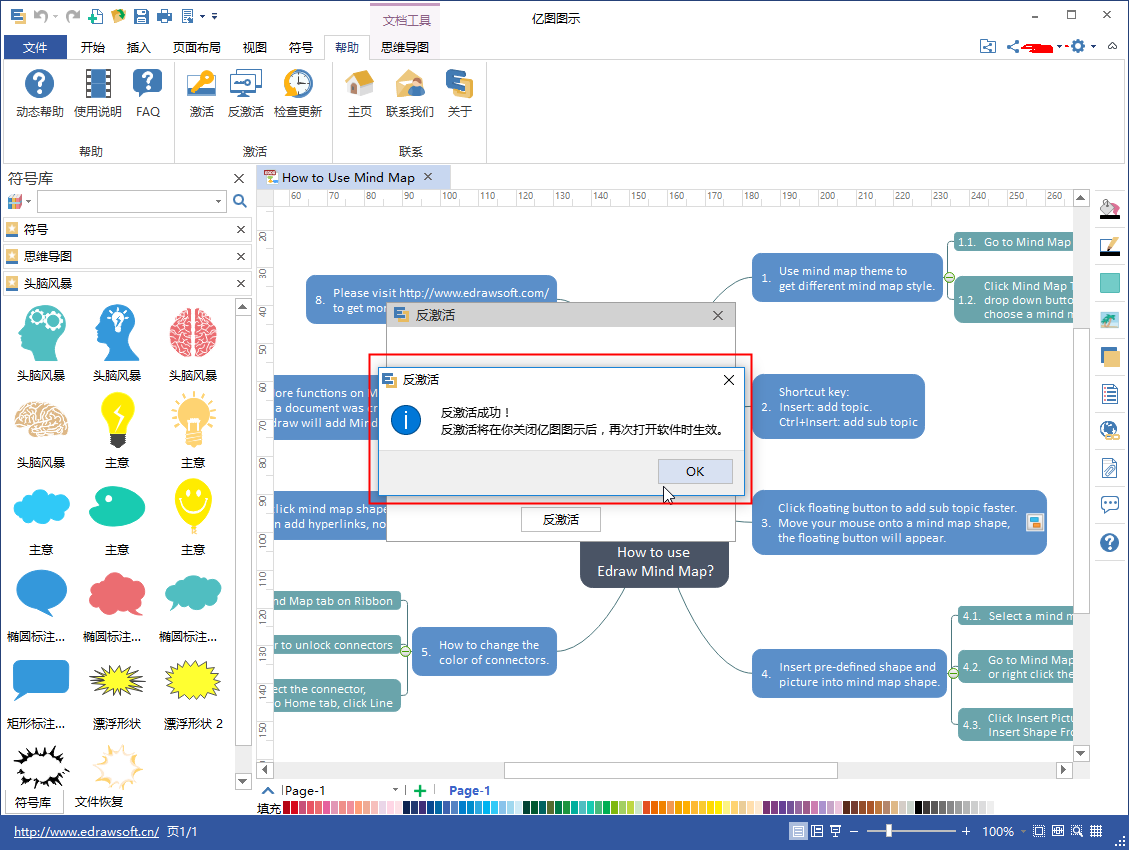
第一步:点击软件上方菜单栏“帮助”中的“反激活”,然后系统会弹出一个提示框,确认信息后点击“反激活”。
第二步:当提示反激活成功后,软件会自动关闭。
第三步:再次打开软件,软件就显示为试用版本的了。
接下来你就可以任意的换电脑,重装系统了。当这一切都准备完毕,软件也重新下载、安装好了,最后只需要按照一般的激活方法,使用原来的产品密钥激活软件就可以了!
总而言之,如果你要换电脑了,请提前进行反激活;如果你的电脑需要重装系统,也请提前反激活。
温馨提示:首次反激活即刻生效,以后再进行反激活则需30天的冷却期。
未发布 GIS软件开发工具包TatukGIS Developer Kernel 发布 v11.3.0-Unstable1丨附下载 TatukGIS Developer Kernel(DK)是一个用于开发自定义地理信息系统(GIS)应用程序以及解决方案的综合性软件开发工具包(SDK)。众所周知,构建一个庞大的地理信息系统需要花费大量的金钱和人力,而TatukGIS却是同类产品中性价比最高的控件,TatukGIS Developer Kernel DK因其功能强大,价格适中,已被超过 50个国家的个人、公司、以及政府等客户用来实现其地理信息系统解决方案。根据不同地首选开发环境,本产品分别以五个独立产品的形式提供(即VCL、.NET/WPF、ActiveX、Compact Framework和ASP.NET),各个产品使用相同的框架、应用程序编程接口(API)技术。
TatukGIS Developer Kernel更新至v11.3.0-Unstable1。Delphi、.NET、ActiveX和ASP.NET版本现已合并,此次更新皆适用于以上版本。
未发布 Web集成工具Thinfinity® VirtualUI™ v2.0发布丨附下载 Cybele Software,Inc.发布Thinfinity VirtualUI v2.0版。该产品让开发Windows桌面环境的应用程序变得更加容易、快速和实惠。使用Thinfinity VirtualUI,可以将现有源代码添加一行,以便通过任何操作系统和任何设备上运行的任何HTML5客户端都可以使用虚拟化GUI。
传统的桌面到网络转换过程需要大量的时间和金钱投入,并且需要执行大量的重新编码。这迫使许多公司和开发商将这一昂贵的转型搁置下来。但是,这也意味着他们会丢失无数潜在的用户。
许多开发人员希望他们的桌面平台移动到网络上。在两个平台Windows 和 HTML5上无需两倍工作量。使用Thinfinity VirtualUI就不用维护多个源代码版本。附加的Thinfinity VirtualUI代码不会影响在Window环境中运行的应用程序。
增强最终用户访问架构,允许以以下一种或多种方法进行匿名或身份验证的访问:Windows登录、OAuth/2、RADIUS或使用Thinfinity Authentication API的自定义身份验证方法。
文件系统和注册表虚拟化帮助开发人员为每个最终用户创建安全、受控和独立的环境,映射或仅公开相关应用程序文件夹和注册表项。
会话记录/播放以保存应用程序会话并稍后重播。会话记录有许多场景:复制问题、应用演示和教程、技术支持、审计监控、电子学习等。
通过增加这些功能,Thinfinity VirtualUI v2.0实现了独特的虚拟化和集成级别。
要求:
Thinfinity VirtualUI与.NET、Delphi、C ++和支持Win32 GDI/GDI + API和ActiveX/COM接口的任何编程语言集成。
所需硬件包括运行Windows 8或更高版本(32位/64位)或Server 2012的网关服务器和运行Windows 8或更高版本(32位/64位)或Server 2012的一个或多个服务器。
客户端设备需要符合HTML5标准的Web浏览器,例如IE10 / 11、Chrome、Safari或Firefox。



 沪公网安备31011202009668号 | 沪ICP备13020027号-2
沪公网安备31011202009668号 | 沪ICP备13020027号-2